开源软件名称:crawlab
开源软件地址:https://gitee.com/crawlab-team/crawlab
开源软件介绍:
Crawlab        中文 | English 安装 | 运行 | 截图 | 架构 | 集成 | 比较 | 相关文章 | 社区&赞助 | 更新日志 | 免责声明 基于Golang的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。 查看演示 Demo | 文档 | 文档 (v0.6-beta) 安装三种方式: - Docker(推荐)
- 直接部署(了解内核)
- Kubernetes (多节点部署)
要求(Docker)- Docker 18.03+
- MongoDB 3.6+
- Docker Compose 1.24+ (可选,但推荐)
要求(直接部署)- Go 1.15+
- Node 12.20+
- MongoDB 3.6+
- SeaweedFS 2.59+
快速开始请打开命令行并执行下列命令。请保证您已经提前安装了 docker-compose。 git clone https://github.com/crawlab-team/examplescd examples/docker/basicdocker-compose up -d 接下来,您可以看看 docker-compose.yml (包含详细配置参数),以及参考 文档 来查看更多信息。 运行Docker请用docker-compose来一键启动,甚至不用配置 MongoDB 数据库,当然我们推荐这样做。在当前目录中创建docker-compose.yml文件,输入以下内容。 version: '3.3'services: master: image: crawlabteam/crawlab:latest container_name: crawlab_example_master environment: CRAWLAB_NODE_MASTER: "Y" CRAWLAB_MONGO_HOST: "mongo" volumes: - "./.crawlab/master:/root/.crawlab" ports: - "8080:8080" depends_on: - mongo worker01: image: crawlabteam/crawlab:latest container_name: crawlab_example_worker01 environment: CRAWLAB_NODE_MASTER: "N" CRAWLAB_GRPC_ADDRESS: "master" CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer" volumes: - "./.crawlab/worker01:/root/.crawlab" depends_on: - master worker02: image: crawlabteam/crawlab:latest container_name: crawlab_example_worker02 environment: CRAWLAB_NODE_MASTER: "N" CRAWLAB_GRPC_ADDRESS: "master" CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer" volumes: - "./.crawlab/worker02:/root/.crawlab" depends_on: - master mongo: image: mongo:latest container_name: crawlab_example_mongo restart: always 然后执行以下命令,Crawlab主节点、工作节点+MongoDB 就启动了。打开http://localhost:8080就能看到界面。 Docker部署的详情,请见相关文档。 直接部署请参考相关文档。 截图登陆页
主页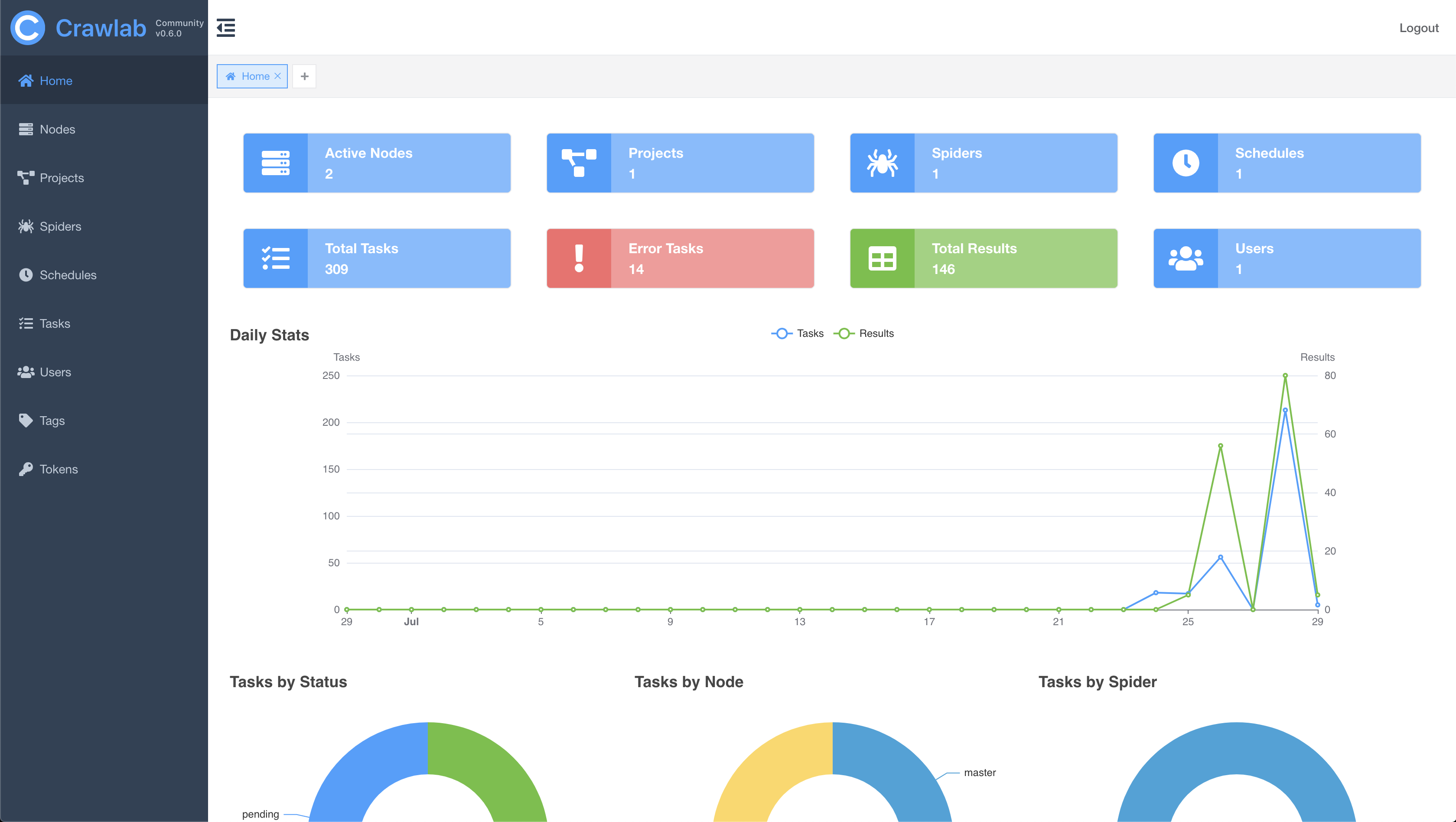
节点列表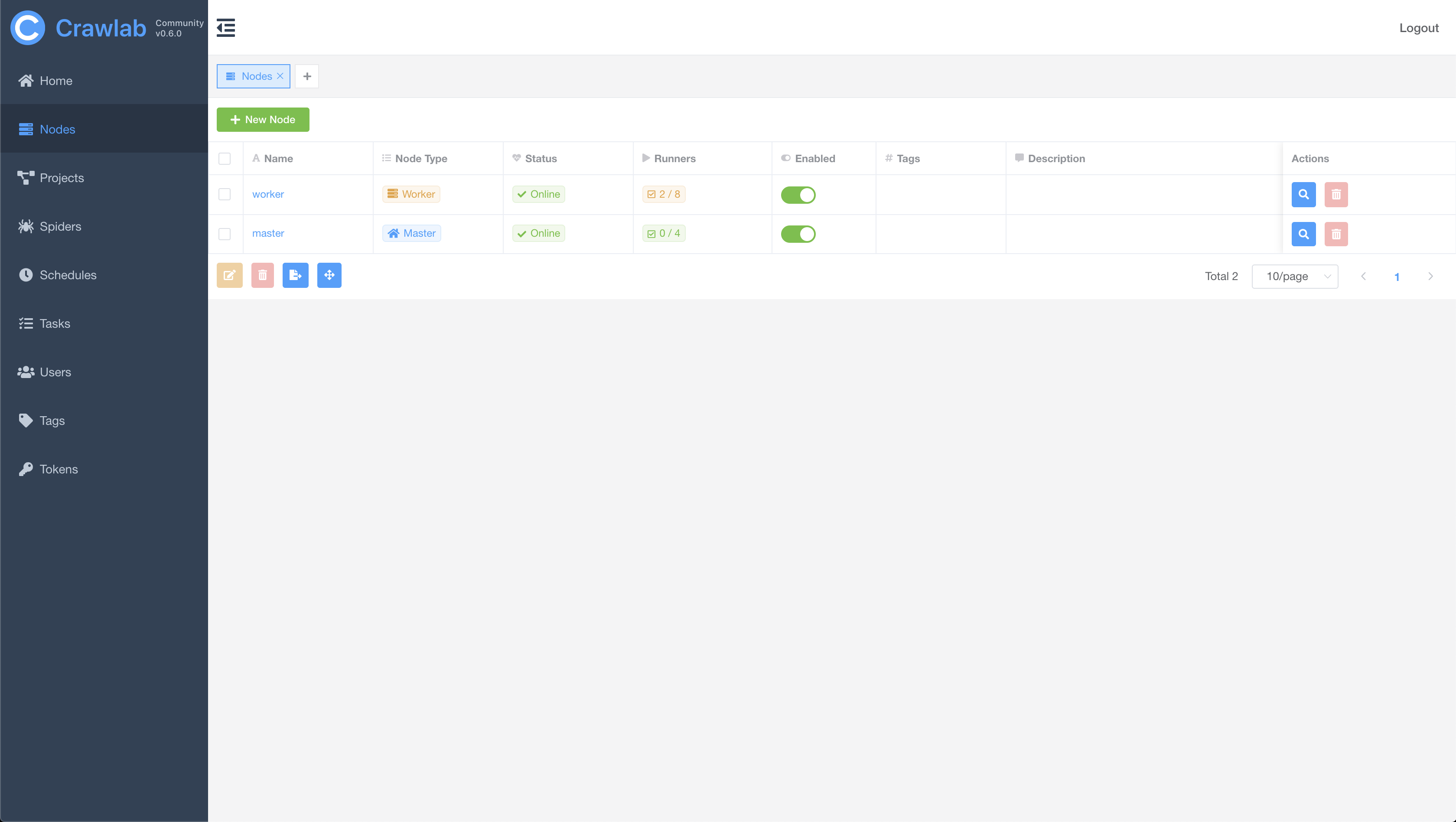
爬虫列表
爬虫概览
爬虫文件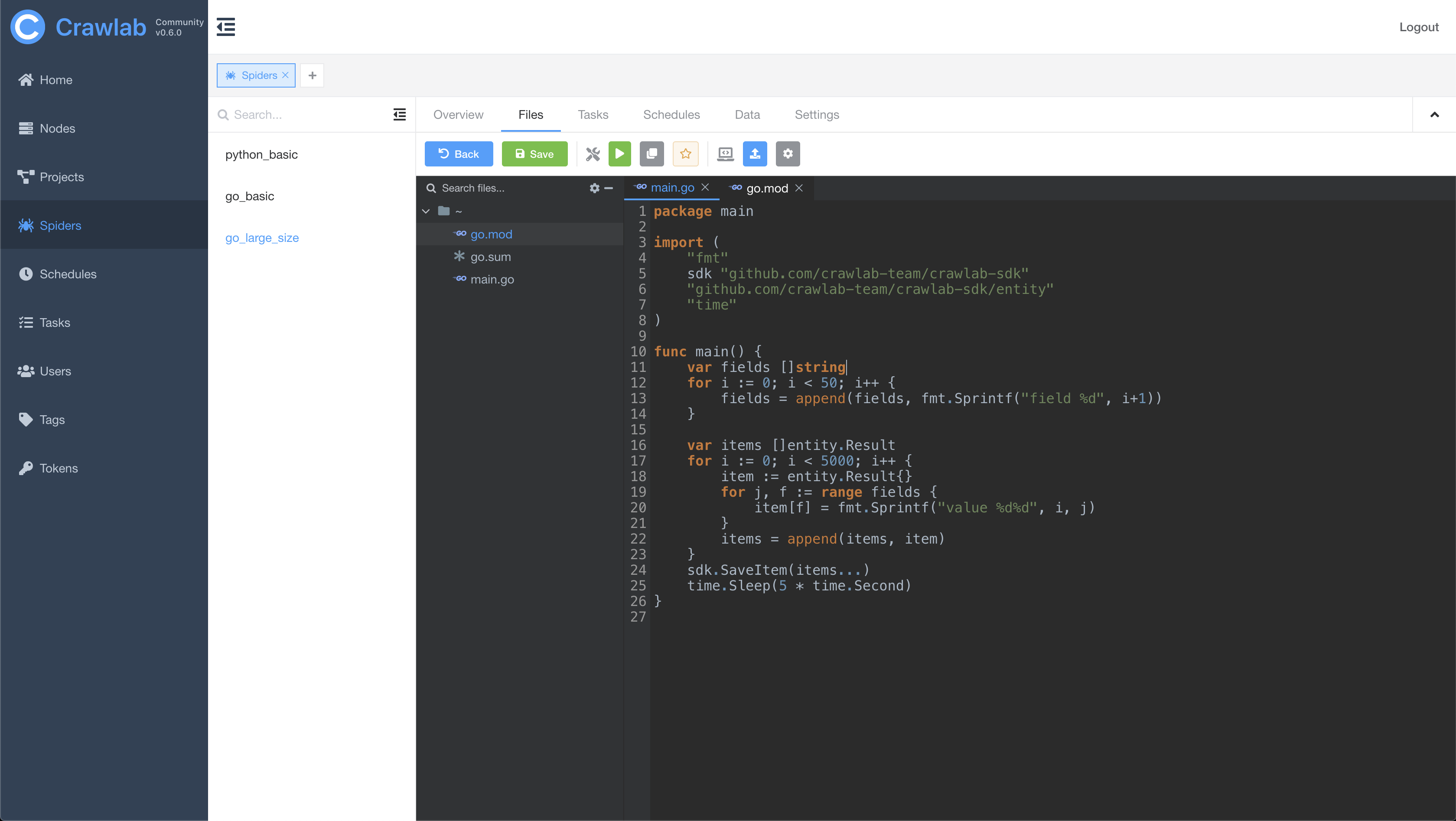
任务日志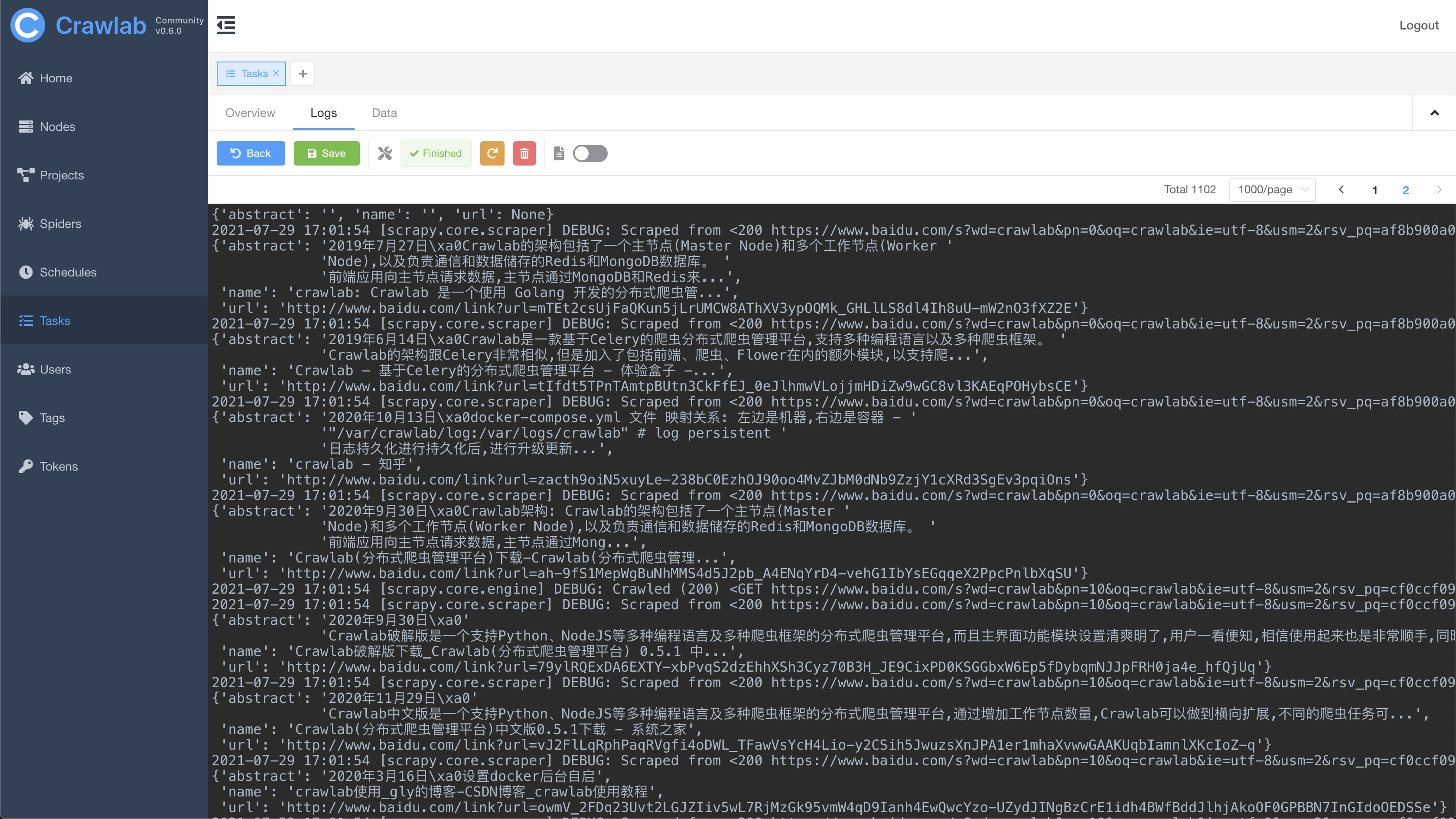
任务结果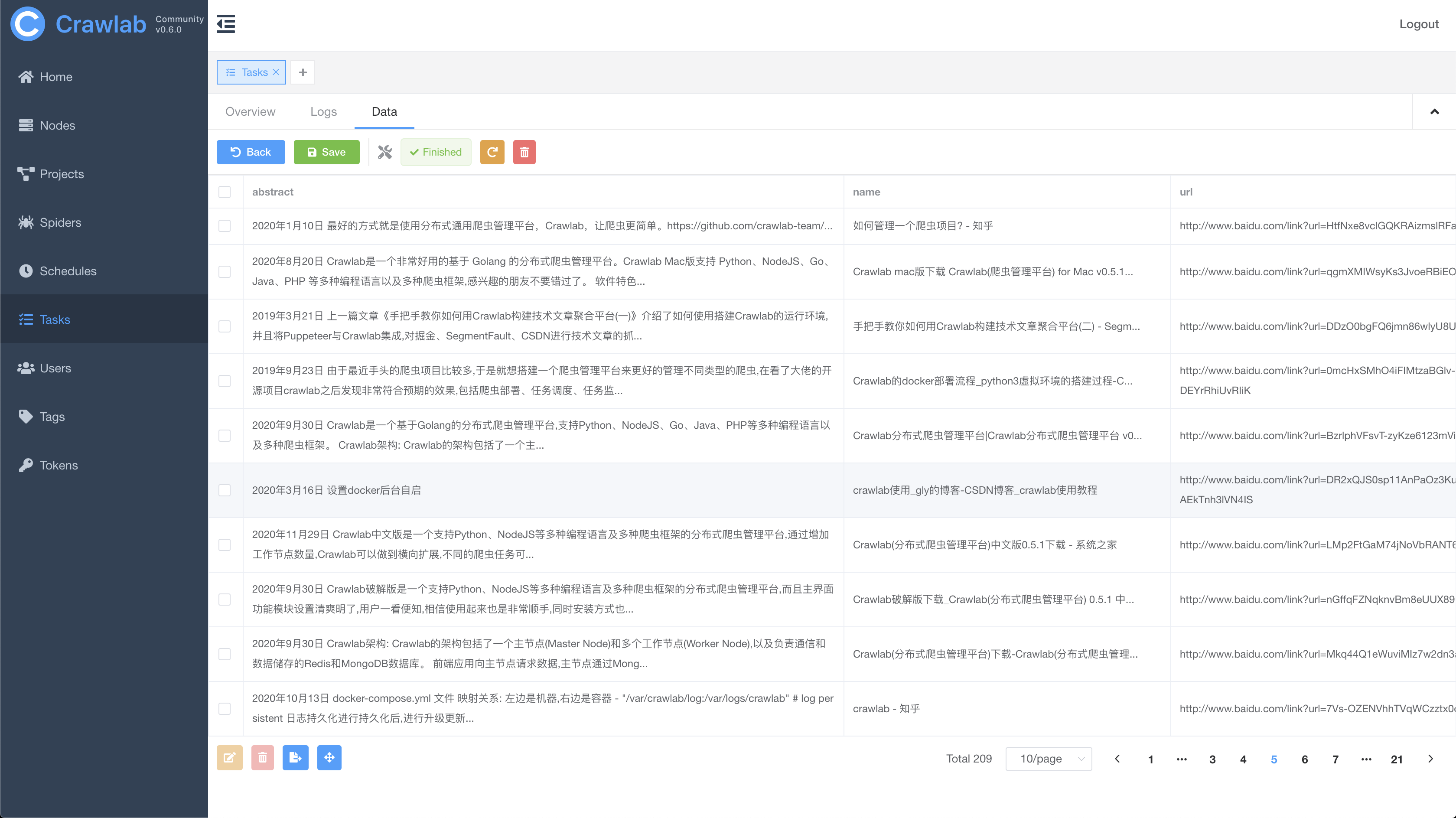
定时任务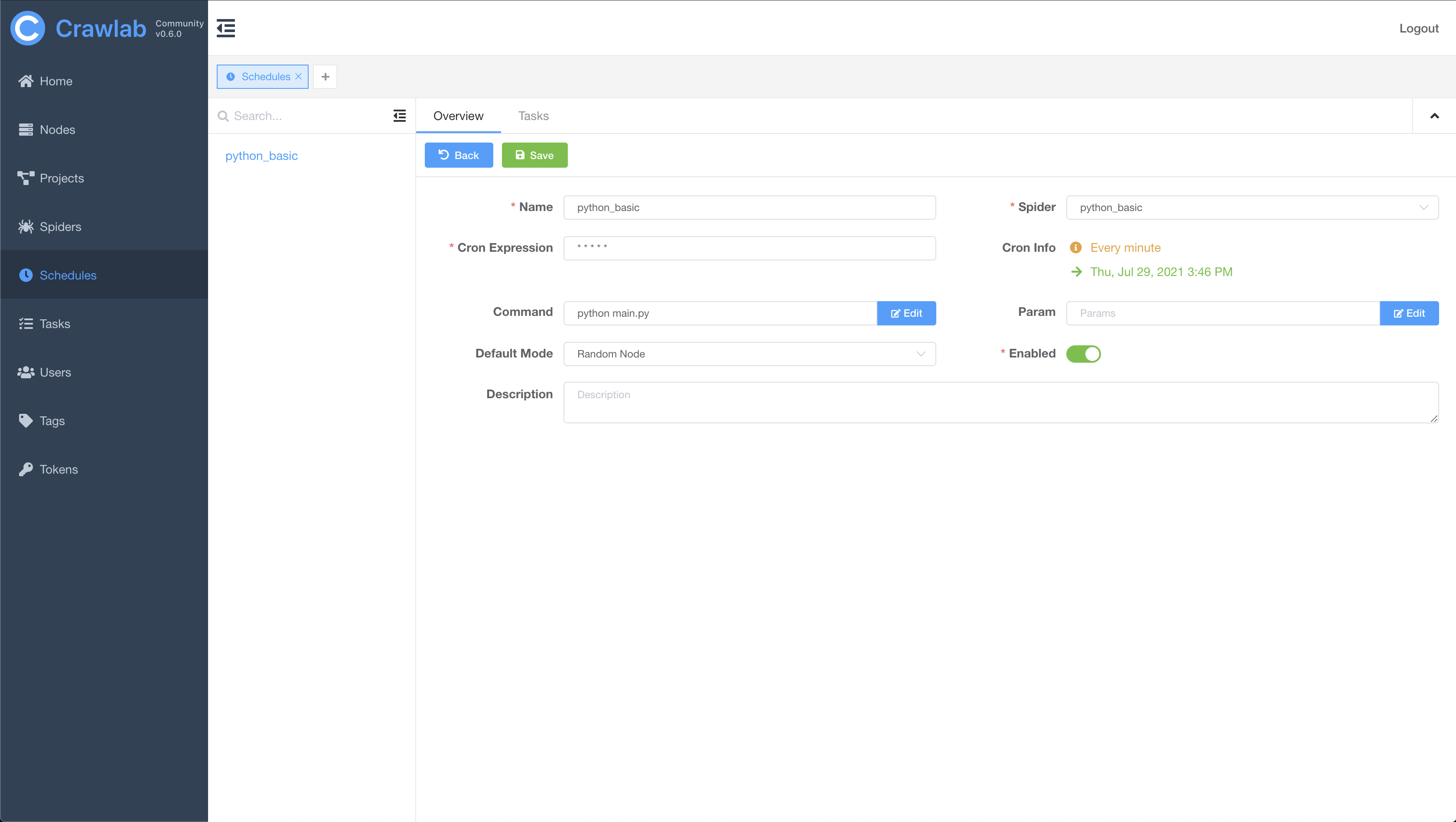
架构Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及 SeaweeFS (分布式文件系统) 和 MongoDB 数据库。 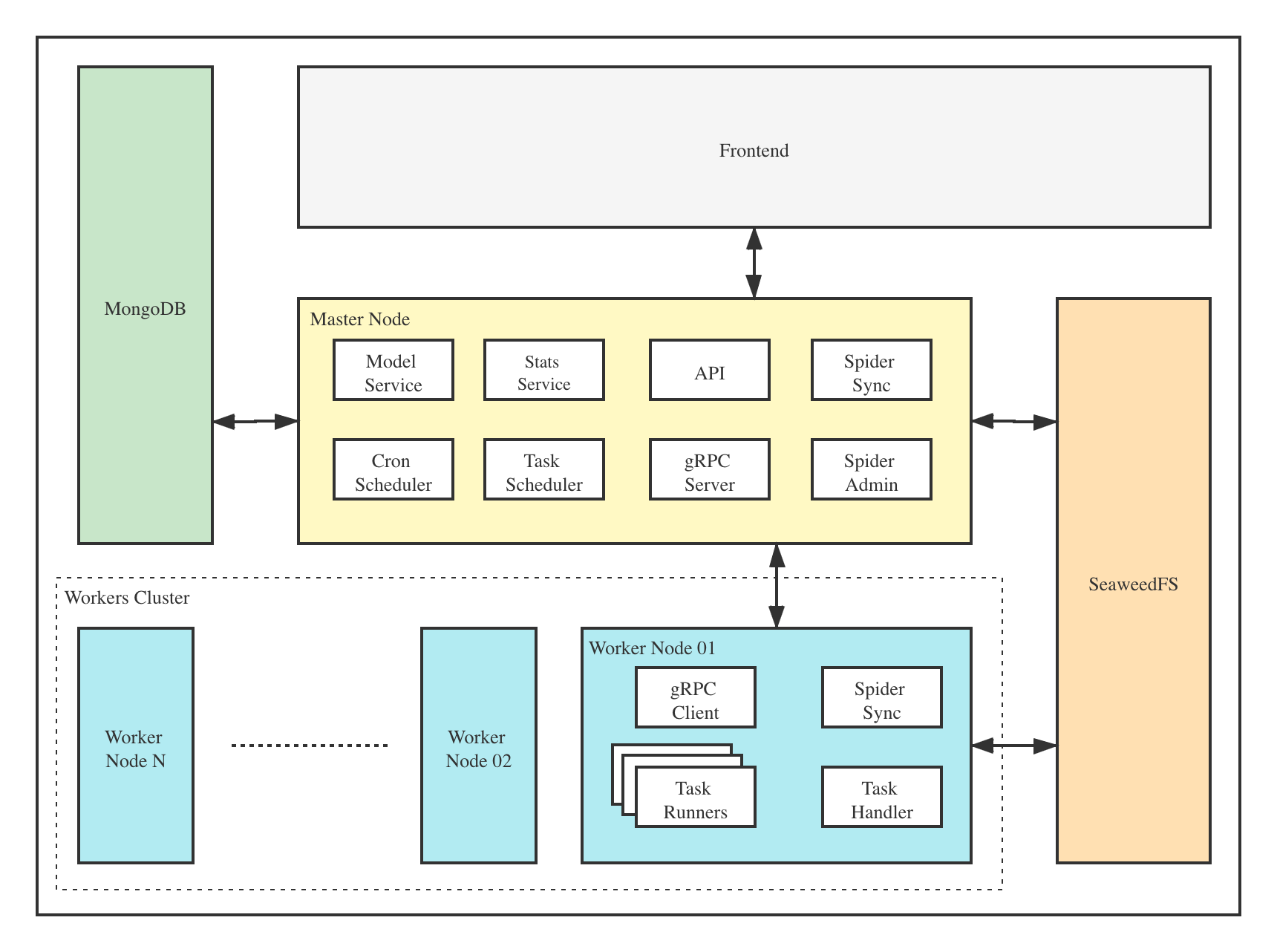
前端应用与主节点 (Master Node) 进行交互,主节点与其他模块(例如 MongoDB、SeaweedFS、工作节点)进行通信。主节点和工作节点 (Worker Nodes) 通过 gRPC (一种 RPC 框架) 进行通信。任务通过主节点上的任务调度器 (Task Scheduler) 进行调度分发,并被工作节点上的任务处理模块 (Task Handler) 接收,然后分配到任务执行器 (Task Runners) 中。任务执行器实际上是执行爬虫程序的进程,它可以通过 gRPC (内置于 SDK) 发送数据到其他数据源中,例如 MongoDB。 主节点主节点是整个Crawlab架构的核心,属于Crawlab的中控系统。 主节点主要负责以下功能: - 爬虫任务调度
- 工作节点管理和通信
- 爬虫部署
- 前端以及API服务
- 执行任务(可以将主节点当成工作节点)
主节点负责与前端应用进行通信,并将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫到分布式文件系统 SeaweedFS,用于工作节点的文件同步。 工作节点工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的PubSub跟主节点通信。通过增加工作节点数量,Crawlab可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。 MongoDBMongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据。任务队列也储存在 MongoDB 里。 SeaweedFSSeaweedFS 是开源分布式文件系统,由 Chris Lu 开发和维护。它能在分布式系统中有效稳定的储存和共享文件。在 Crawlab 中,SeaweedFS 主要用作文件同步和日志存储。 前端Frontend app is built upon Element-Plus, a popular Vue 3-based UI framework. It interacts with API hosted on the Master Node, and indirectly controls Worker Nodes. 前端应用是基于 Element-Plus 构建的,它是基于 Vue 3 的 UI 框架。前端应用与主节点上的 API 进行交互,并间接控制工作节点。 与其他框架的集成Crawlab SDK 提供了一些 helper 方法来让您的爬虫更好的集成到 Crawlab 中,例如保存结果数据到 Crawlab 中等等。 集成 Scrapy在 settings.py 中找到 ITEM_PIPELINES(dict 类型的变量),在其中添加如下内容。 ITEM_PIPELINES = { 'crawlab.scrapy.pipelines.CrawlabPipeline': 888,}然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 任务详情 -> 数据 里。 通用 Python 爬虫将下列代码加入到您爬虫中的结果保存部分。 # 引入保存结果方法from crawlab import save_item# 这是一个结果,需要为 dict 类型result = {'name': 'crawlab'}# 调用保存结果方法save_item(result)然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 任务详情 -> 数据 里。 其他框架和语言爬虫任务实际上是通过 shell 命令执行的。任务 ID (Task ID) 作为环境变量 CRAWLAB_TASK_ID 被传入爬虫任务进程中,从而抓取的数据可以跟任务管理。 与其他框架比较现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab? 因为很多现有当平台都依赖于Scrapyd,限制了爬虫的编程语言以及框架,爬虫工程师只能用scrapy和python。当然,scrapy是非常优秀的爬虫框架,但是它不能做一切事情。 Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。 | 框架 | 技术 | 优点 | 缺点 | Github 统计数据 |
|---|
| Crawlab | Golang + Vue | 不局限于 scrapy,可以运行任何语言和框架的爬虫,精美的 UI 界面,天然支持分布式爬虫,支持节点管理、爬虫管理、任务管理、定时任务、结果导出、数据统计、消息通知、可配置爬虫、在线编辑代码等功能 | 暂时不支持爬虫版本管理 |   | | ScrapydWeb | Python Flask + Vue | 精美的 UI 界面,内置了 scrapy 日志解析器,有较多任务运行统计图表,支持节点管理、定时任务、邮件提醒、移动界面,算是 scrapy-based 中功能完善的爬虫管理平台 | 不支持 scrapy 以外的爬虫,Python Flask 为后端,性能上有一定局限性 |   | | Gerapy | Python Django + Vue | Gerapy 是崔庆才大神开发的爬虫管理平台,安装部署非常简单,同样基于 scrapyd,有精美的 UI 界面,支持节点管理、代码编辑、可配置规则等功能 | 同样不支持 scrapy 以外的爬虫,而且据使用者反馈,1.0 版本有很多 bug,期待 2.0 版本会有一定程度的改进 |   | | SpiderKeeper | Python Flask | 基于 scrapyd,开源版 Scrapyhub,非常简洁的 UI 界面,支持定时任务 | 可能有些过于简洁了,不支持分页,不支持节点管理,不支持 scrapy 以外的爬虫 |   |
贡献者       社区 & 赞助如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信 tikazyq1 并注明"Crawlab",作者会将你拉入群。或者,您可以扫下方支付宝二维码给作者打赏去升级团队协作软件或买一杯咖啡。    |

 客服电话
客服电话
 APP下载
APP下载

 官方微信
官方微信













请发表评论